
※本記事はプロモーションを含みます。
「Excelの検索と行列関数って、全部で何種類あるの?」
「VLOOKUPの代わりに、新しい関数を使いこなしたい!」
Excel (Office 365/Microsoft 365)には、データを扱う作業効率を劇的に高める検索と行列関数が全41種類あります。
この関数群は、データの検索、抽出、並べ替え、結合、整形といった、ビジネスで最も頻繁に行う作業を自動化するための「核」となる機能です。
検索と行列関数とは?
Excelの関数の中でも、大量のデータから必要な情報を見つけ出し(検索)たり、データの形や位置を操作・変換(行列)したりする役割を担う関数群
特に、Office 365/Microsoft 365で追加された「ダイナミック配列関数(スピル機能)」に対応した新しい関数は、従来のVLOOKUPやINDEXの常識を塗り替えるほど強力です。
検索と行列関数 全41種類 詳細解説
| 関数の分類 | 関数名 | 構文 | 関数の使い方 |
| 検索・位置特定 | XLOOKUP | =XLOOKUP(検索値, 検索配列, 戻り配列, [見つからない場合], [一致モード], [検索モード]) | 垂直/水平方向の検索を行い、対応する値を返す。VLOOKUP/HLOOKUP/INDEX+MATCHの機能を集約した最新関数。 |
| VLOOKUP | =VLOOKUP(検索値, 範囲, 列番号, [検索方法]) | 範囲の左端の列で検索値を探し、指定した列の値を返す。 | |
| HLOOKUP | =HLOOKUP(検索値, 範囲, 行番号, [検索方法]) | 範囲の最上行で検索値を探し、指定した行の値を返す。 | |
| 位置特定 | XMATCH | =XMATCH(検索値, 検索配列, [一致モード], [検索モード]) | 検索配列内で、検索値が何番目にあるかを返す。MATCH関数の最新版で、既定値が完全一致。 |
| MATCH | =MATCH(検索値, 検査範囲, [照合のタイプ]) | 検査範囲内で、検索値が何番目にあるかを返す。 | |
| 参照・取得 | INDEX | =INDEX(配列, 行番号, [列番号], [領域番号]) | 配列または範囲内の、指定した行と列が交差する位置のセルの値を返す。 |
| OFFSET | =OFFSET(基準, 行数, 列数, [高さ], [幅]) | 基準セルから指定された行数・列数だけ離れたセルまたは範囲を返す(参照として使用)。 | |
| INDIRECT | =INDIRECT(参照文字列, [A1形式]) | テキスト文字列として入力された参照を、実際のセル参照として評価する。 | |
| CHOOSE | =CHOOSE(インデックス, 値1, [値2], …) | インデックス番号に基づいて、引数として渡された複数の値の中から対応する値を返す。 | |
| 情報取得 | ADDRESS | =ADDRESS(行番号, 列番号, [参照の種類], [参照形式], [シート名]) | 指定された行番号と列番号に対応するセル参照をテキスト文字列として返す。 |
| COLUMN | =COLUMN([参照]) | 指定されたセルの列番号を返す。引数を省略すると、関数が入力されたセルの列番号を返す。 | |
| COLUMNS | =COLUMNS(配列) | 指定された配列または範囲に含まれる列の総数を返す。 | |
| ROW | =ROW([参照]) | 指定されたセルの行番号を返す。引数を省略すると、関数が入力されたセルの行番号を返す。 | |
| ROWS | =ROWS(配列) | 指定された配列または範囲に含まれる行の総数を返す。 | |
| AREAS | =AREAS(参照) | 指定された参照に含まれる領域(非連続な範囲)の総数を返す。 | |
| FORMULATEXT | =FORMULATEXT(参照) | 指定したセルに入力されている数式をテキスト文字列として返す。 | |
| その他 | HYPERLINK | =HYPERLINK(リンク先, [表示名]) | 指定されたリンク先へのハイパーリンクを作成し、表示名をセルに表示する。 |
| FIELDVALUE | =FIELDVALUE(値,フィールド名) | 株式データ型などが設定されたセルのフィールド値を抽出する。 | |
| GETPIVOTDATA | =GETPIVOTDATA(データF,PT,[F1,I1,…]) | ピボットテーブルから特定の集計データを取得する。 | |
| TRIMRANGE | =TRIMRANGE(配列) | 周囲の空白行・列を除去したデータ範囲を返す。 | |
| IMAGE | =IMAGE(リンク,[代替テキスト]) | 指定されたURLの画像をセル内に表示する。 | |
| 動的配列 | TRANSPOSE | =TRANSPOSE(配列) | 配列の行と列を入れ替えて返す(転置)。 |
| FILTER | =FILTER(配列, 含む, [空の場合]) | 指定された条件を満たす行または列を抽出して返す。 | |
| SORT | =SORT(配列, [並べ替えインデックス], [並べ替え順序], [列で並べ替え]) | 配列または範囲全体を、指定した列を基準に並べ替えて返す。 | |
| SORTBY | =SORTBY(配列, 基準配列1, [並べ替え順序1], [基準配列2], …) | 配列全体を、配列外の別の範囲の値に基づいて並べ替えて返す。 | |
| UNIQUE | =UNIQUE(配列, [列の比較], [一度のみ]) | 配列または範囲内の重複しない一意な値のリストを返す。 | |
| SEQUENCE | =SEQUENCE(行, [列], [開始], [ステップ]) | 指定された行数と列数の連続した数値の配列を生成する。 | |
| RANDARRAY | =RANDARRAY(行, [列], [最小値], [最大値], [整数]) | 指定された行数と列数の乱数の配列を生成する。 | |
| VSTACK | =VSTACK(配列1, [配列2], …) | 複数の配列や範囲を縦方向に積み重ねて返す。 | |
| HSTACK | =HSTACK(配列1, [配列2], …) | 複数の配列や範囲を横方向に結合して返す。 | |
| TAKE | =TAKE(配列, 行数, [列数]) | 配列の先頭または末尾から、指定した行数・列数だけを取り出す。 | |
| DROP | =DROP(配列, 行数, [列数]) | 配列の先頭または末尾から、指定した行数・列数だけを削除し、残りを返す。 | |
| CHOOSECOLS | =CHOOSECOLS(配列, 列番号1, [列番号2], …) | 配列から、指定した列番号に対応する列のみを抽出する。 | |
| CHOOSEROWS | =CHOOSEROWS(配列, 行番号1, [行番号2], …) | 配列から、指定した行番号に対応する行のみを抽出する。 | |
| TOCOL | =TOCOL(配列, [無視する値], [スキャン方法]) | 配列または範囲を、縦一列のリストに変換する。 | |
| TOROW | =TOROW(配列, [無視する値], [スキャン方法]) | 配列または範囲を、横一列のリストに変換する。 | |
| WRAPROWS | =WRAPROWS(ベクトル, ラップカウント, [パディング]) | ベクトルを、指定した数ごとに行方向に折り返して行列に変換する。 | |
| WRAPCOLS | =WRAPCOLS(ベクトル, ラップカウント, [パディング]) | ベクトルを、指定した数ごとに列方向に折り返して行列に変換する。 | |
| EXPAND | =EXPAND(配列, 行数, 列数, [パディング]) | 配列を指定サイズに拡張し、不足セルをパディング値で埋める。 | |
| 集計・分析 | GROUPBY | =GROUPBY(行フィールド, 値, 集計関数, [ヘッダー], …) | 行フィールドを基準にデータをグループ化し、指定した集計関数で結果を返す。 |
| PIVOTBY | =PIVOTBY(行F, 列F, 値, 集計関数, [行ヘッダー], …) | 行フィールドと列フィールドを基準にクロス集計(ピボット)を行う。 | |
| 外部連携 | FILTERXML | =FILTERXML(XML, XPath) | 指定されたXMLコンテンツに対してXPath式を実行し、マッチした値を返す。 |
| ENCODEURL | =ENCODEURL(テキスト) | URLとして使用するために、テキストをURLエンコードする。 | |
| WEBSERVICE | =WEBSERVICE(URL) | 指定されたURLのWebサービスからデータを取得する。 | |
| PY | =PY(Pythonコード) | セル内で直接Pythonコードを実行し、その結果を返す。 |
I. 検索・位置特定・参照系の関数(Lookup & Index)
表の中から目的の値を探したり、セルの位置を取得したりする関数群です。
1. XLOOKUP
概要:
VLOOKUPやHLOOKUPを置き換える検索関数です。検索範囲と結果範囲を別々に指定でき、検索方向やエラー処理、一致モードなどを柔軟に設定できます。
構文:
=XLOOKUP(検索値,検索範囲,戻り配列,[見つからない場合],[一致モード],[検索モード])
例題:
「社員リスト」を使用してIDから氏名を検索します。
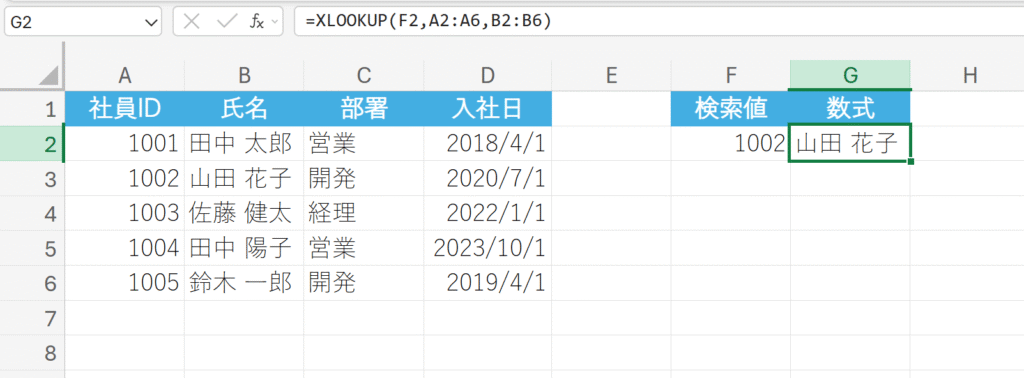
解説:
社員IDの列(A2:A6)から「1002」を探し、同じ行にある氏名の列(B2:B6)の値「山田 花子」を返します。
2. VLOOKUP
概要:
表の左端の列を垂直方向(V)に検索し、対応する値を取り出す伝統的な関数です。
構文:
=VLOOKUP(検索値,範囲,列番号,[検索方法])
例題:
社員IDを指定して、対応する内線番号を取得してみましょう。
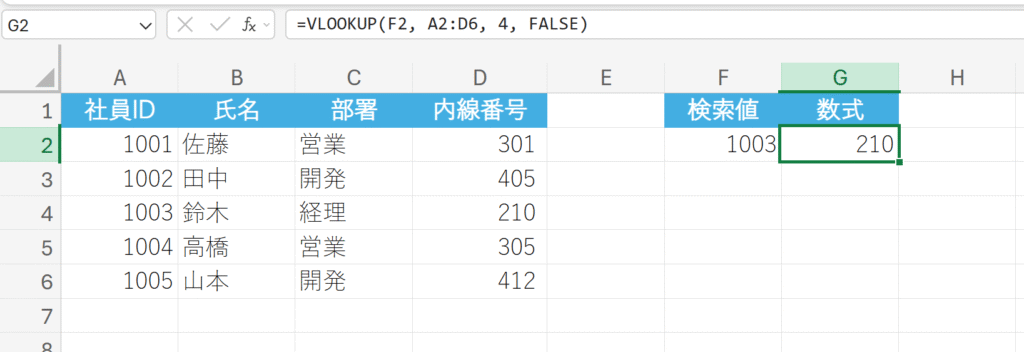
解説:
A列(範囲の左端)から検索値1003を探します。1003が見つかった行の、4列目にある値(内線番号 210)を返します。FALSEを指定することで、完全に一致する値だけを検索します。
3. HLOOKUP
概要: 表の先頭行を水平方向(H)に検索し、対応する値を取り出す関数です。
構文:
=HLOOKUP(検索値,範囲,行番号,[検索方法])
例題:
四半期名から売上高を検索する。
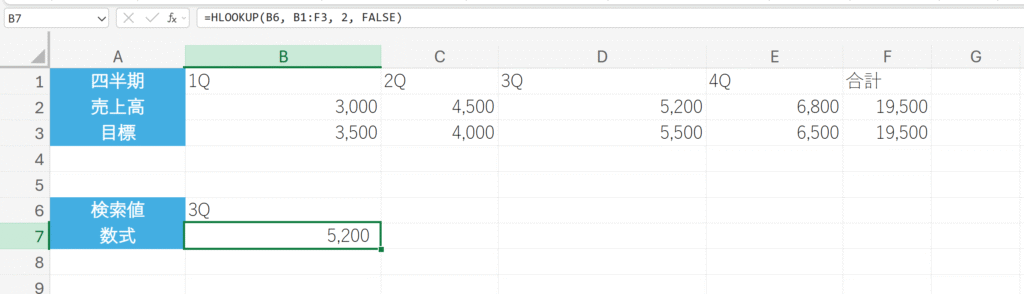
解説:
1行目(範囲の先頭行)から検索値”3Q”を探します。”3Q”が見つかった列の、2行目にある値(売上高 5,200)を返します。FALSEを指定することで、完全に一致する値だけを検索します。
4. LOOKUP
概要:
VLOOKUPやHLOOKUPより古い形式の検索関数で、主に近似一致の検索に使用されます。
構文:
=LOOKUP(検索値,検査ベクトル,[結果ベクトル])
例題:
得点を指定して、対応する評価を取得します。
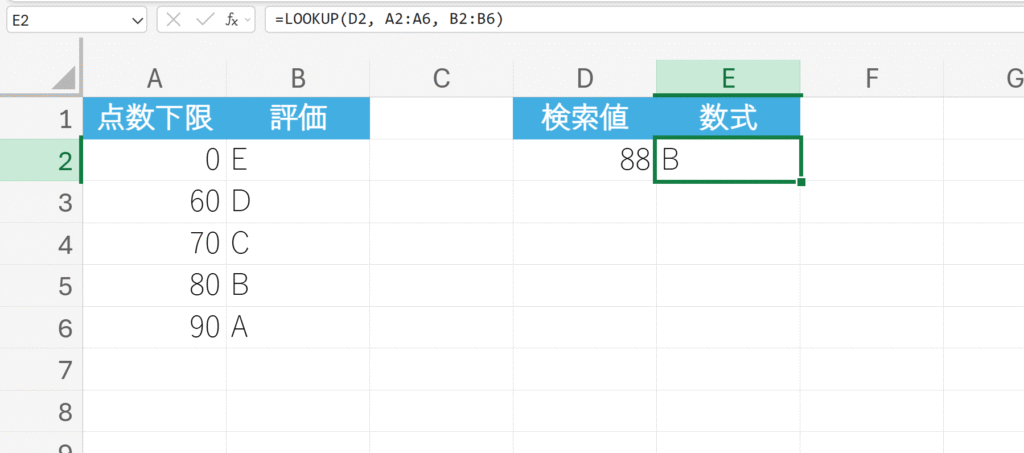
解説:
検査ベクトル(A2:A6)から検索値”88″以下の最大値を探します。”90″は超えてしまうため”80″が該当します。”80″がある位置と同じ位置にある、結果ベクトル(B2:B6)の値「B」を返します。
重要:LOOKUP関数(ベクトル形式)を使用する場合、検査ベクトルは必ず昇順(小さい順)に並べ替えておく必要があります。
5. INDEX
概要:
配列またはセル範囲から、指定した行番号と列番号の交差する位置にある値を返します。MATCHと組み合わせてよく使われます。
構文:
=INDEX(配列,行番号,[列番号])
例題:
「開発」部署の「2Q売上」の値”950″を取り出します。
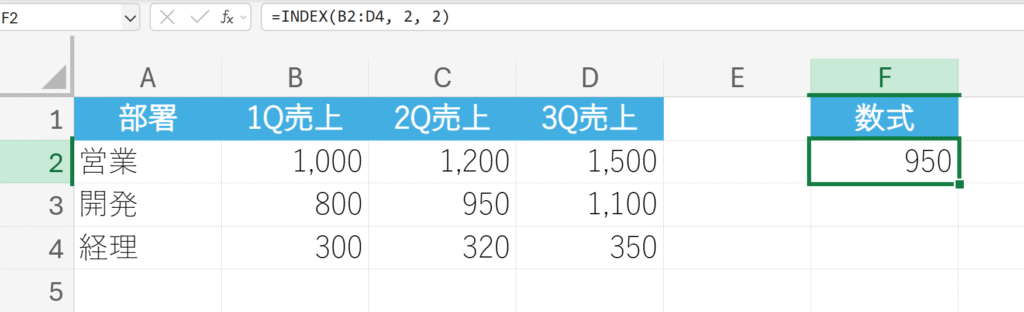
解説:
範囲B2:B4の中から、2行目(開発)と2列目(2Q売上)の交点にある値を返します。
6. XMATCH
概要:
MATCHを置き換える位置検索関数です。検索値が範囲内の相対的な位置(何番目か)を返します。
構文:
=XMATCH(検索値,検索範囲,[一致モード],[検索モード])
例題:
「経理」という文字列がリストの何番目に現れるかを知りたい場合。
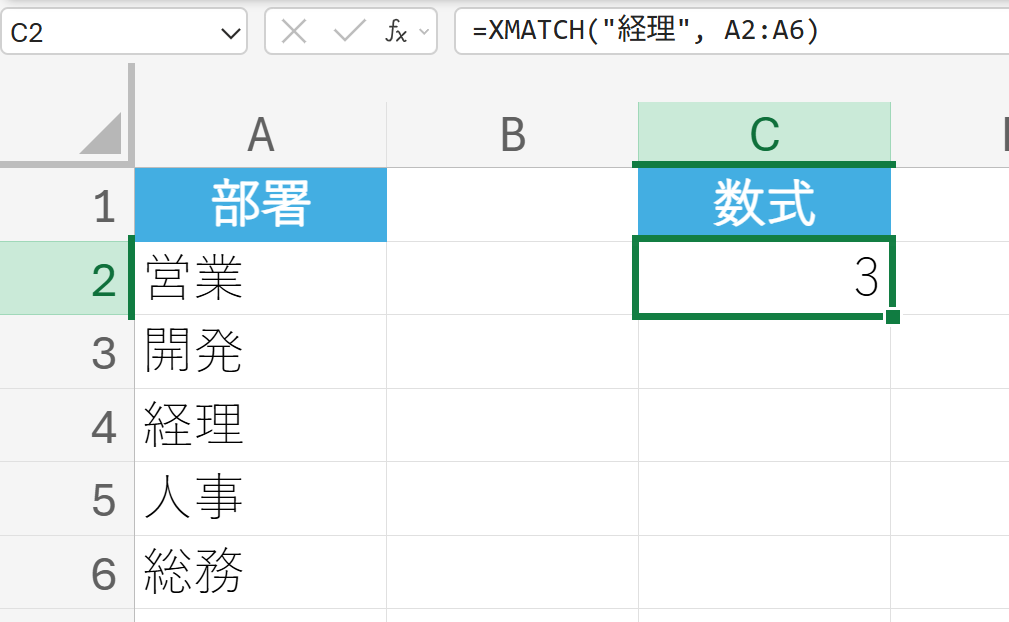
解説:
A2からA6の範囲の中で、「経理」は上から3番目にあるため、「3」という位置(インデックス)を返します。
7. MATCH
概要:
検索値が範囲内の相対的な位置(何番目か)を返します。INDEX関数と組み合わせて使われることが多いです。
構文:
=MATCH(検索値,検索範囲,[一致の種類])
例題:
「みかん」という商品名が、リストの何番目に現れるかを知りたい場合。
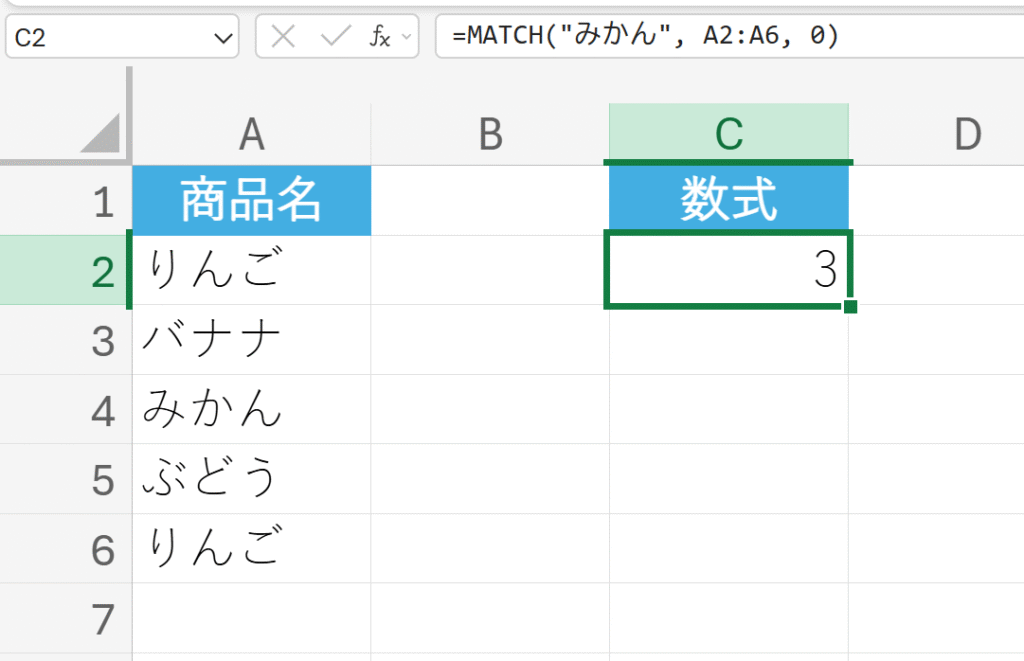
解説:
A2からA6の範囲の中で、「みかん」は上から3番目にあるため、「3」という位置(インデックス)を返します。もし同じ商品名が複数あっても、MATCHは最初に見つかった位置を返します。(例:「りんご」を検索すると「1」を返します。)
8. GETPIVOTDATA
概要:
ピボットテーブルから、指定したフィールドと項目に対応する集計データを取り出すことができます。
構文:
=GETPIVOTDATA(データフィールド,ピボットテーブル,[フィールド1,項目1,…])
例題:
ピボットテーブルから「売上高」の「東京支店」の値を検索します。
9. FIELDVALUE
概要:
株式や地理データなどのデータ型(データタイプ)から、指定したフィールド(属性)の値を取り出します。
構文:
=FIELDVALUE(値,フィールド名)
例題:株価(Price)を取得する
以下のデータ型が設定されたセルを考えます。
- A1セルに、テキスト
"Google"が入力されています。 - A1セルに対して、Excelの「データ型」機能を使って「Stocks(株式)」データ型が適用され、セルが変換されています。
この状態のA1セルには、株価、ティッカーシンボル、時価総額など、Google社の多数の情報が紐づいています。
A1セルに紐づいた情報から、現在の株価(Price)を取得します。
| 引数 | 設定値 | 意味 |
| 値 | A1 | データ型が設定されているセル(Google株の情報) |
| フィールド名 | "Price" | 抽出したい情報の名前(株価) |
数式:=FIELDVALUE(A1, “Price”)
結果:145.50 (※ 例としての架空の株価)
解説:
- FIELDVALUEは、セルA1の「株式」データ型にアクセスします。
- そのデータ型に格納されているフィールド「Price」の値(現在の株価)を抽出して表示します。
II. ダイナミック配列操作系の関数(Dynamic Array Functions)
Office 365で新たに追加された、複数のセルに結果をスピルさせる強力な関数群です。
10. FILTER
概要:
指定した条件に一致する行または列を抽出し、新しい配列として返します。これがデータ抽出の主流になりつつあります。
構文:
=FILTER(配列,含む,[空の場合])
例題:
特定の地域(東京)のデータのみを抽出する。
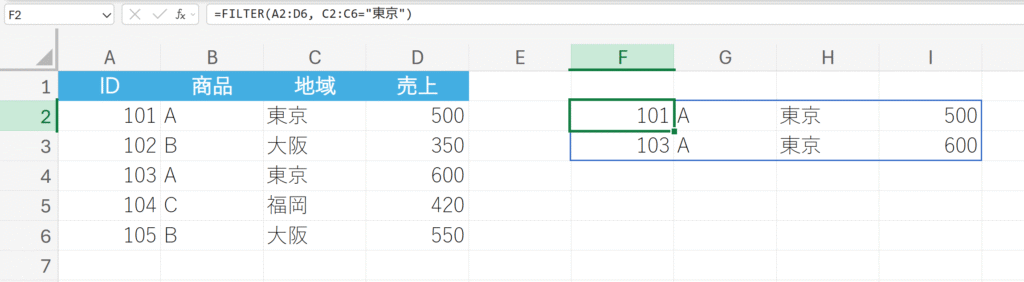
解説:
配列としてA2:D6全体を指定します。含むで指定した条件C2:C6=”東京”は、条件に合う行に対してTRUEを返します。FILTER関数はTRUEとなった行全体(ID、商品、地域、売上)を抽出し、動的に表示します。
11. UNIQUE
概要:
配列や範囲の中から、重複しない一意な値だけを取り出して返します。動的なドロップダウンリスト作成などに非常に便利です。
構文:
=UNIQUE(配列,[列の比較],[回数指定])
例題:
部署名の重複を排除してリストを作成する。
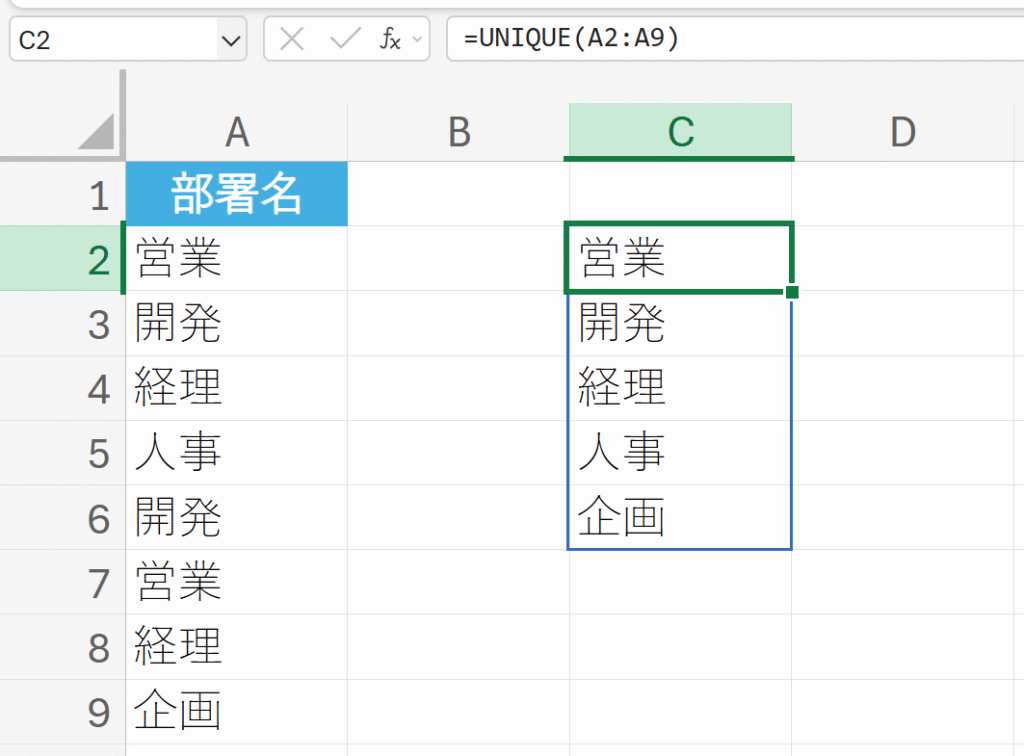
解説:
- UNIQUE関数はA2:A9の範囲を検索します。
- 「営業」「開発」「経理」のように複数回出現する値も、最初に出現した値のみを結果に含め、重複する値は排除されます。
12. SORT
概要:
配列や範囲のデータを、指定した列を基準に並べ替えて新しい配列として返します。
構文:
=SORT(配列,[並べ替えインデックス],[並べ替え順序],[並べ替え基準])
例題:
売上を基準に降順で並べ替える。
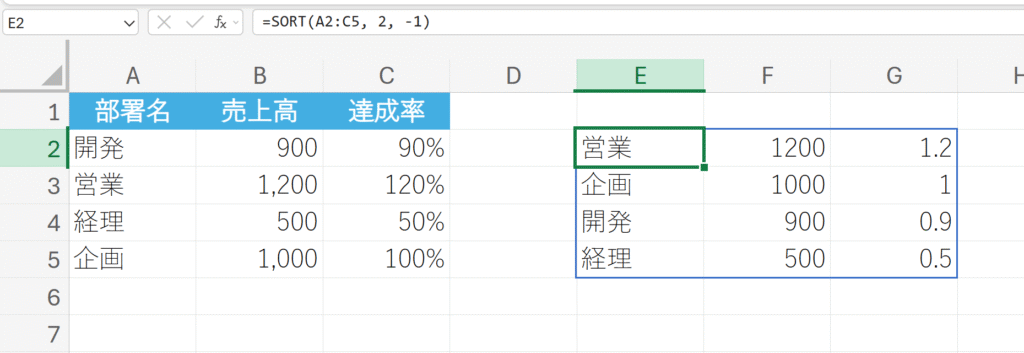
解説:
A2:C5の配列全体が、2列目(売上)の数値に基づいて降順に並べ替えられました。昇順(小さい順)で並べ替えたい場合は、第3引数に1(または省略)を指定します。
13. SORTBY
概要:
配列を、別の配列(キー)を基準にして並べ替え、結果を元の配列の形で返します。
構文:
=SORTBY(配列,基準配列1,[順序1],[基準配列2,…])
例題:
年齢(外部配列)を基準に氏名リストを並べ替える。
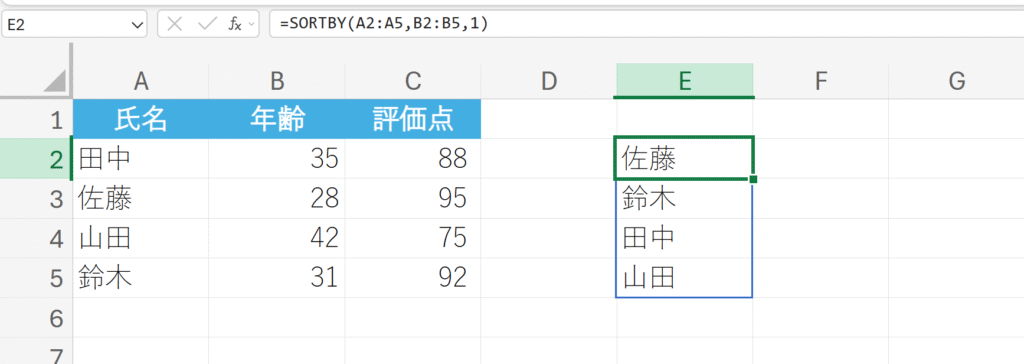
解説:
元のA2:A5(氏名)の順序は変更されません。B2:B5(年齢)が昇順(28→31→35→42)になるように、氏名リストが並べ替えられました。
14. VSTACK
概要:
複数の配列または範囲を垂直方向(縦)に結合(スタック)して、一つの配列として返します。
構文:
=VSTACK(配列1,[配列2,…])
例題:
複数のデータリストを単純に結合する。
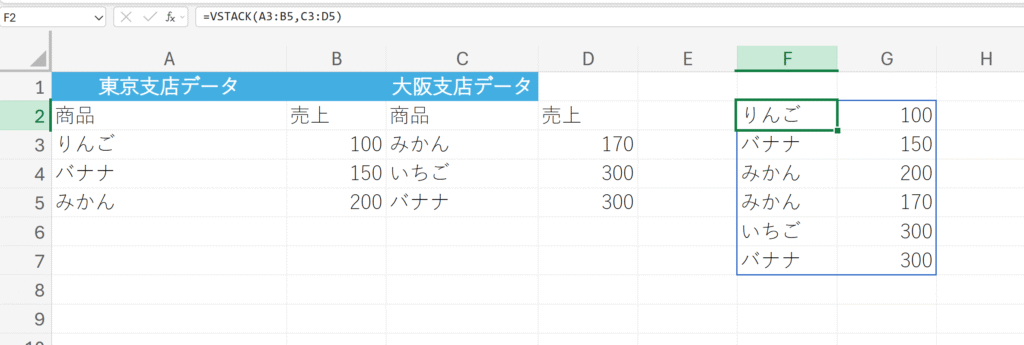
解説:
VSTACKは、配列1のデータの下に、配列2のデータを単純に追加します。この機能は、月ごと、支店ごとなど、別々の場所に分散しているデータを集計前の段階で一つにまとめるのに最適です。
15. HSTACK
概要:
複数の配列または範囲を水平方向(横)に結合(スタック)して、一つの配列として返します。
構文:
=HSTACK(配列1,[配列2,…])
例題:
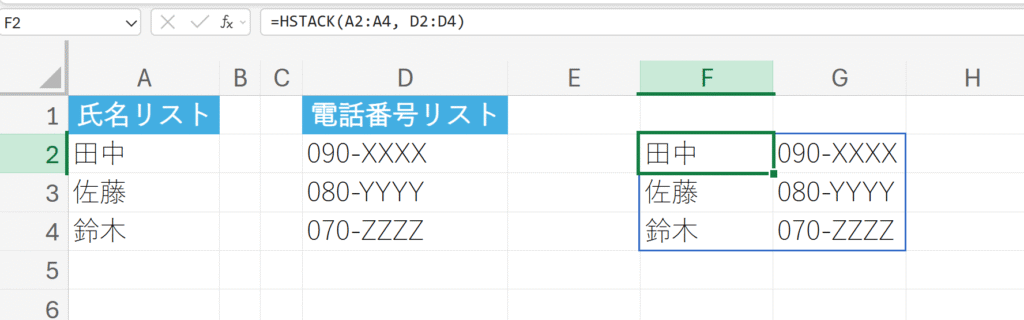
複数のデータリストを単純に横に結合する。
解説:
HSTACKは、配列1のデータの右隣に、配列2のデータを単純に追加(スタック)します。この機能は、計算結果や抽出結果を元のデータとは別の場所にまとめて表示する際に役立ちます。
16. TAKE
概要:
配列の先頭または末尾から、指定した数の行や列を取り出して返します。
構文:
=TAKE(配列,取り出す行数,[取り出す列数])
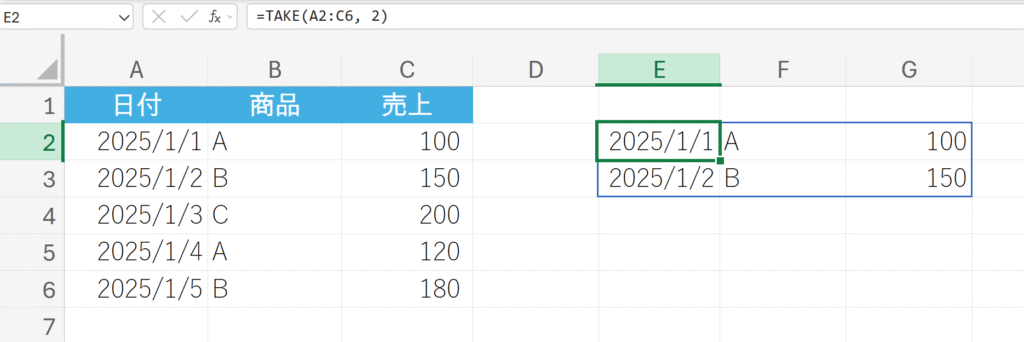
例題:
先頭から2行(最新の2件)を取り出す。
17. DROP
概要:
配列の先頭または末尾から、指定した数の行や列を除外した配列を返します。
構文:
=DROP(配列,削除する行数,[削除する列数])
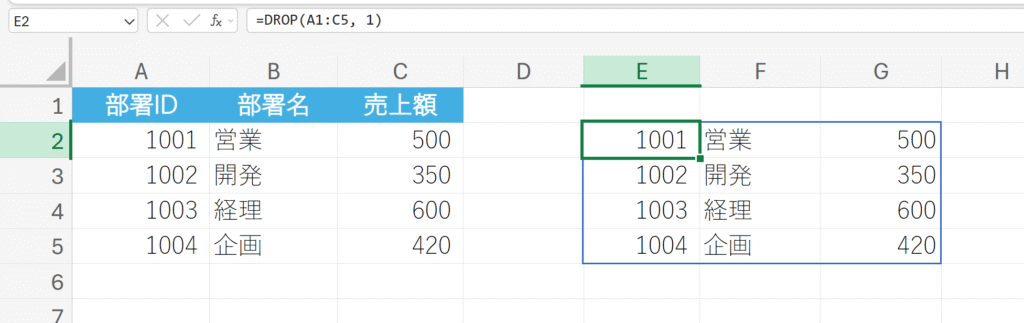
例題:
先頭のヘッダー行を削除する。
解説:
DROP(…, 1)と指定することで、配列の先頭1行が取り除かれました。
18. TOCOL
概要:
配列や範囲を1つの列に変換します。空のセルやエラー値の無視を指定できます。
構文:
=TOCOL(配列,[無視する値,…])
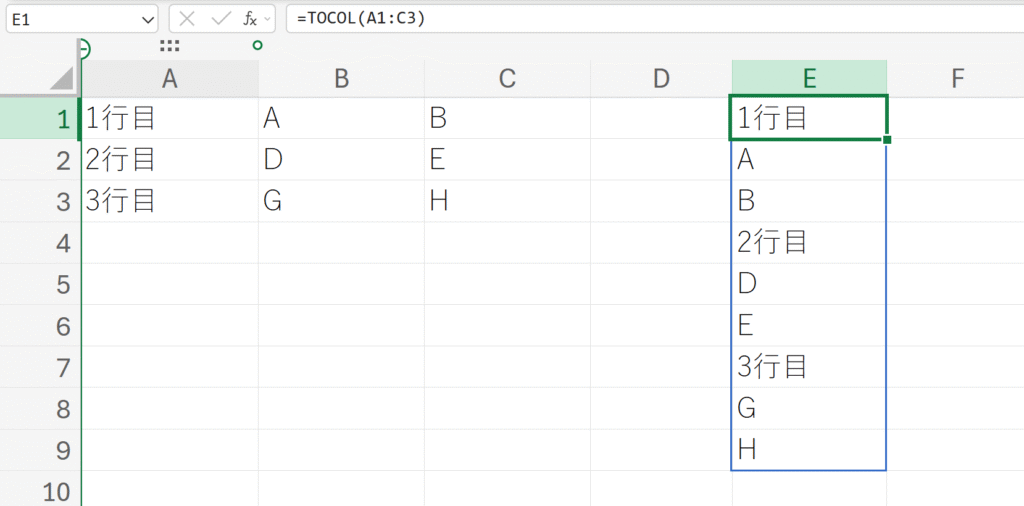
例題:
配列を1つの列に変換する。
解説:
TOCOLは、まずA列(A1, A2, A3)を読み込みます。次にB列(B1, B2, B3)を読み込みます。最後にC列(C1, C2, C3)を読み込み、全てを縦一列に結合します。
19. TOROW
概要:
配列や範囲を1つの行に変換します。空のセルやエラー値の無視を指定できます。
構文:
=TOROW(配列,[無視する値,…])
例題:
配列を1つの行に変換する(列ごとスキャン)。

解説:
TOROWは、既定のスキャン方法(列ごと)に従い、まずA列(A1, A2, A3)を読み込みます。次にB列(B1, B2, B3)を読み込み、最後にC列を読み込み、全てを横一列に結合します。
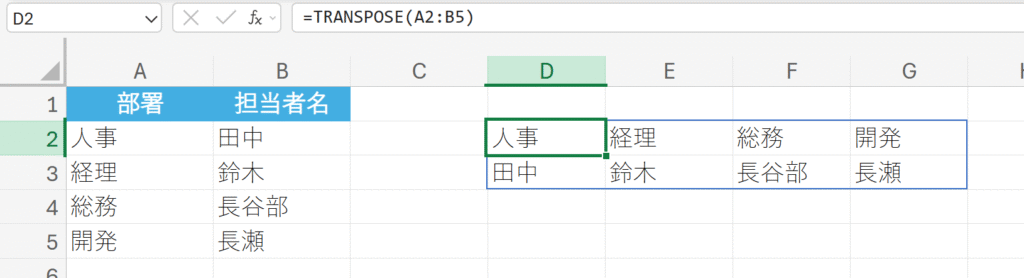
20. TRANSPOSE
概要:
配列や範囲の行と列を入れ替えて(転置して)返します。
構文:
=TRANSPOSE(配列)
例題:
行と列を入れ替える。
21. CHOOSECOLS
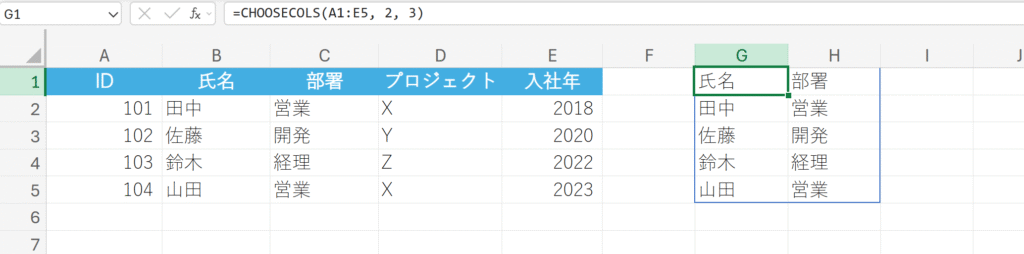
概要:
配列から、指定した列番号のみを選択して新しい配列を返します。
構文:
=CHOOSECOLS(配列,列番号1,[列番号2,…])
例題:
氏名と部署の列のみを取り出す。
22. CHOOSEROWS
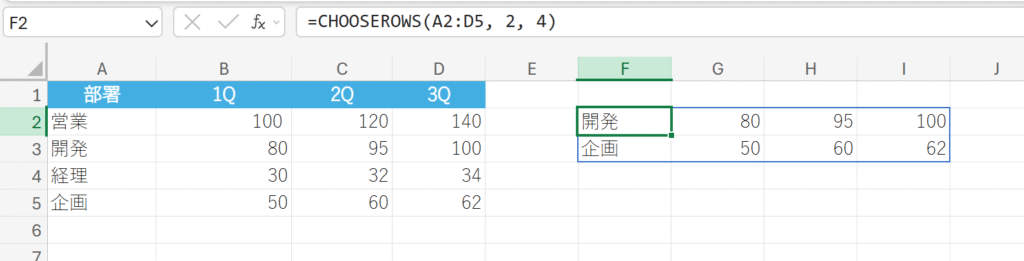
概要:
配列から、指定した行番号のみを選択して新しい配列を返します。
構文:
=CHOOSEROWS(配列,行番号1,[行番号2,…])
例題:
特定の部署の行のみを抽出する。
23. WRAPCOLS
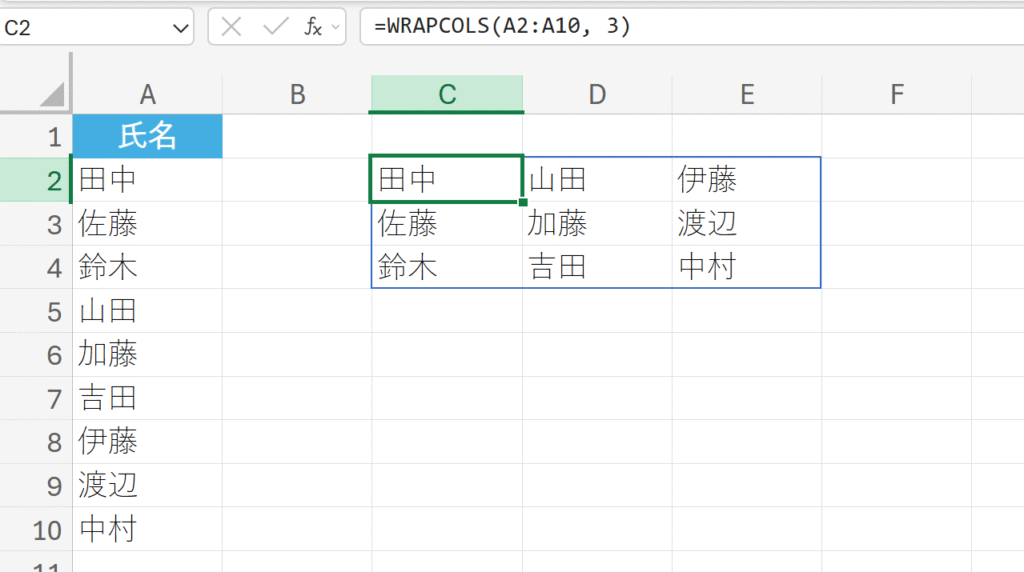
概要:
1次元のデータを、指定した数の列で折り返して2次元の配列に変換します。
構文:
=WRAPCOLS(ベクトル,ラップカウント,[パディング])
例題:
A2:A10の社員リストを、3名ごとに新しい列に折り返して3×3の表形式に変換します。
24. WRAPROWS
概要:
1次元のデータを、指定した数の行で折り返して2次元の配列に変換します。
構文:
=WRAPROWS(ベクトル,ラップカウント,[パディング])
例題:
単一の列に並んだ「社員データ」を3項目ごとに新しい行に折り返す。
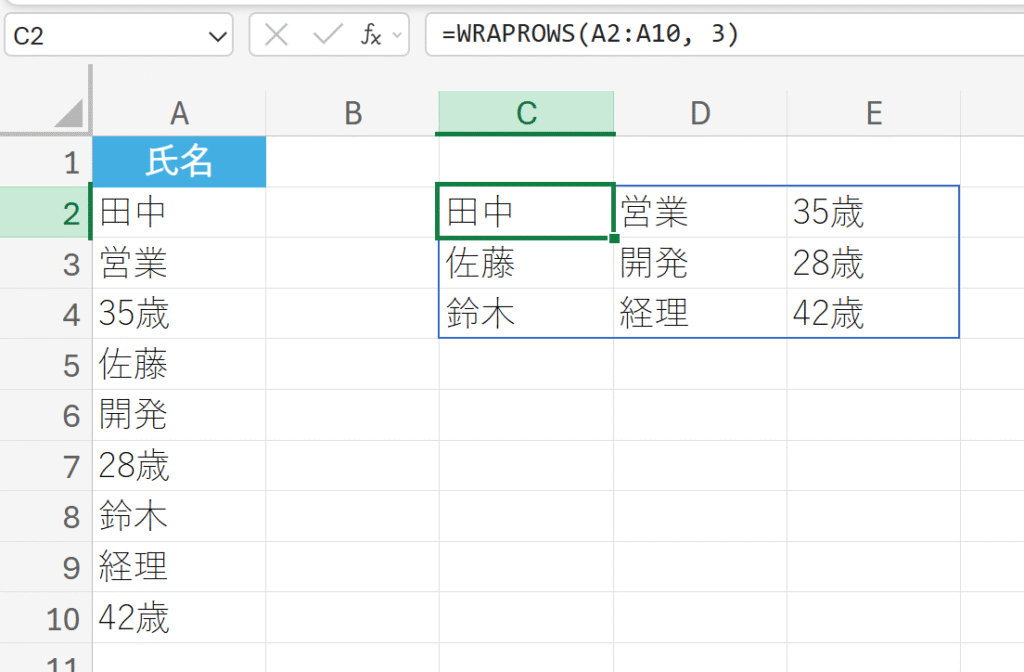
解説:
- WRAPROWSは、最初の3項目(田中、営業、35歳)を1行目に配置します。
- 次の3項目(佐藤、開発、28歳)を2行目に配置します。
- 残りの3項目(鈴木、経理、42歳)を3行目に配置し、3行で配列が完成します。
25. EXPAND
概要:
配列を、指定した行数・列数に拡張します。拡張した部分には指定した値(パディング)が埋められます。
構文:
=EXPAND(配列,行数,列数,[パディング])
例題:
データ配列A1:B2を、4行、3列のサイズに拡張し、不足セルを「-」で埋める。
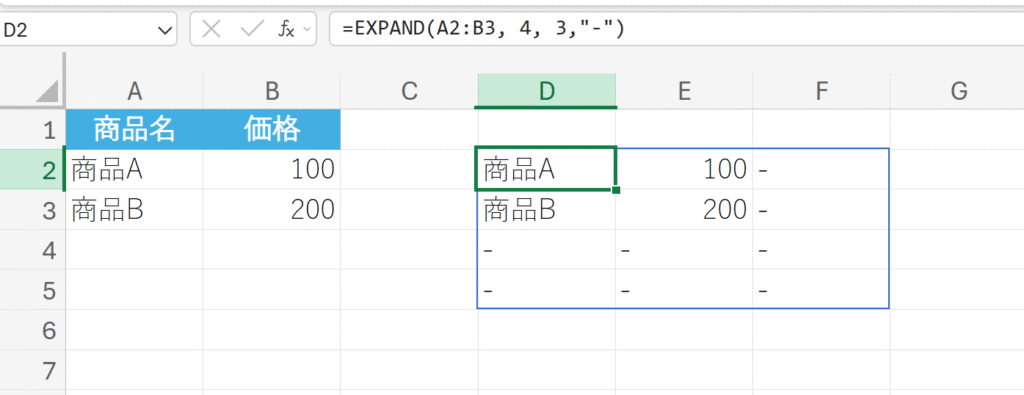
26. GROUPBY
概要:
特定の列で行をグループ化し、集計関数(SUM, AVERAGEなど)を使って結果を配列で返します。
構文:
=GROUPBY(行フィールド,値,集計関数,[ヘッダー,…])
例題:
地域(A列)をグループ化のキーとし、各地域の売上(C列)の合計を計算します。
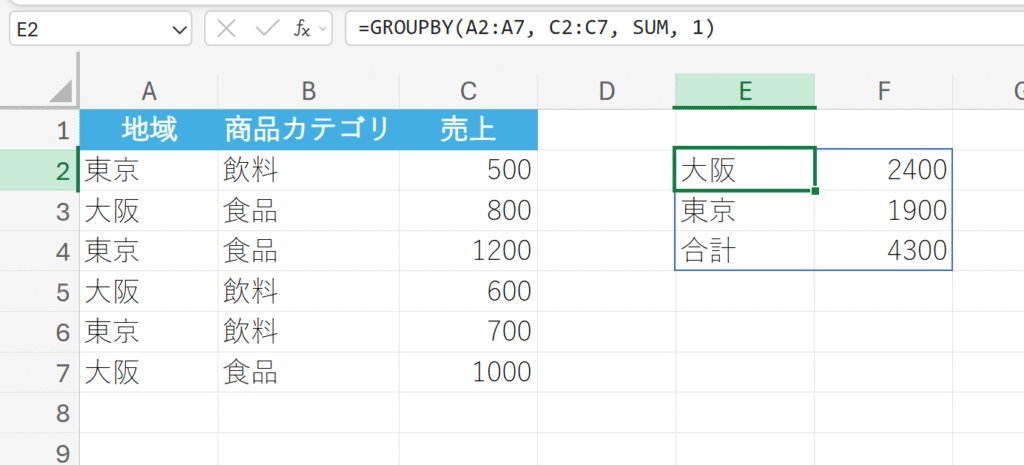
27. PIVOTBY
概要:
行と列でデータをグループ化し、集計関数を使って結果をピボットテーブルのような配列で返します。
構文:
=PIVOTBY(行フィールド,列フィールド,値,集計関数,[ヘッダー,…])
例題:
地域を行フィールド(縦軸)に、商品カテゴリを列フィールド(横軸)に配置し、それぞれの交差点で売上の合計を計算します。
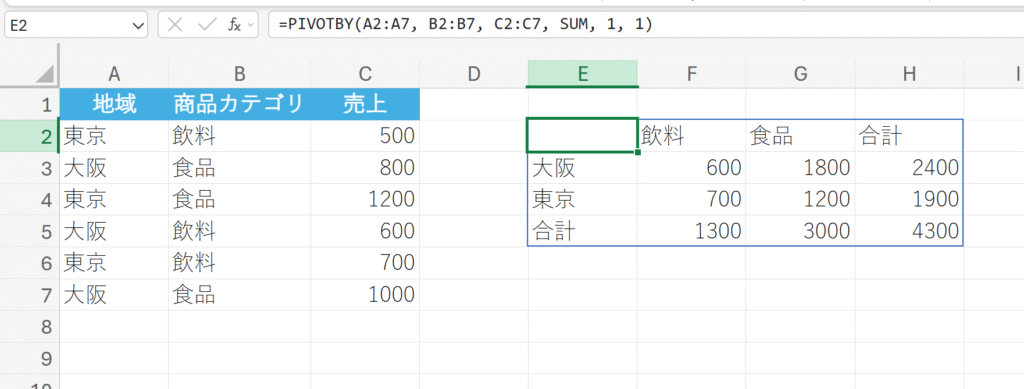
解説:
第5引数(行ヘッダー)と第6引数(列ヘッダー)に”1″を指定することで、元のデータから自動的にヘッダー(地域、商品カテゴリ、SUM of 売上)が結果に挿入されます。
28. PY
概要:
Excelのセル内でPythonコードを実行し、その結果をExcelに返す関数です。(※ Microsoft 365のBeta版などで利用可能な上級者向け関数)
構文:
=PY(Pythonコード)
例題:
NumPyを使った配列の平方根の計算
A1:A5のセル範囲に任意の数値の平方根を計算します。
数式:=PY(“numpy.sqrt(xl(‘A1:A5’))”)
解説:
xl(‘A1:A5’)というExcel独自の表記を使って、対象のセル範囲をPythonコード内で参照します。この範囲がPandas DataFrameとして読み込まれます。NumPyライブラリのsqrt関数で、DataFrame内の各要素の平方根が計算されます。計算結果は新しい配列としてExcelに返されます。
III. セル/範囲の参照・情報取得系の関数
セルの位置情報や、範囲の大きさ、参照文字列などを操作・取得する関数群です。
29. ADDRESS
概要:
指定した行番号と列番号に基づいて、セル参照を文字列として返します。
構文:
=ADDRESS(行番号,列番号,[参照の種類])
例題:
基本的な絶対参照の作成
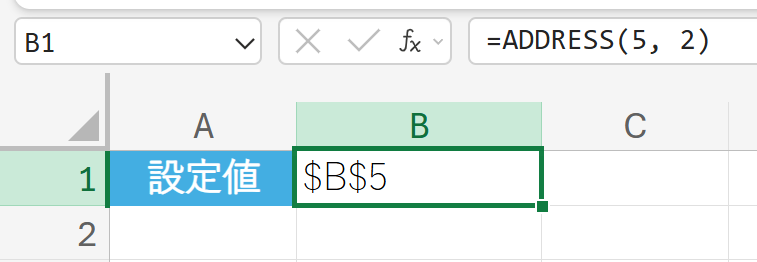
解説:
行番号と列番号を数値で指定すると、対応するセル参照のテキスト文字列が返されます。列番号は、A列が1、B列が2、C列が3… となります。
30. ROW
概要:
指定したセルまたは範囲の行番号を返します。引数を省略すると、関数を入力したセルの行番号を返します。
構文:
=ROW([参照])
例題:
関数が入力されているセルの行番号を取得する。
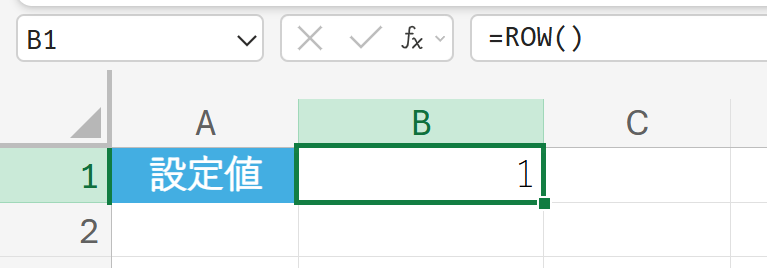
31. ROWS
概要:
指定したセル範囲に含まれる行の数を返します。
構文:
=ROWS(配列)
例題:
データ範囲の行数をカウントする。
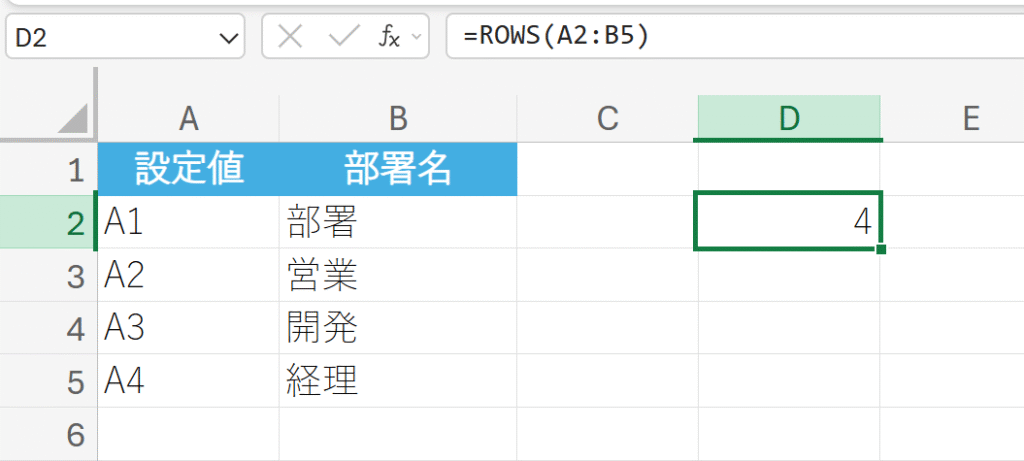
解説:
A1からA4まで、合計で4行あるため、4が返されます。参照に空のセルが含まれていても、参照範囲内のすべての行がカウントされます。
32. COLUMN
概要:
指定したセルまたは範囲の列番号を返します。引数を省略すると、関数を入力したセルの列番号を返します。
構文:
=COLUMN([参照])
例題:
セルC5に以下の数式を入力した場合。
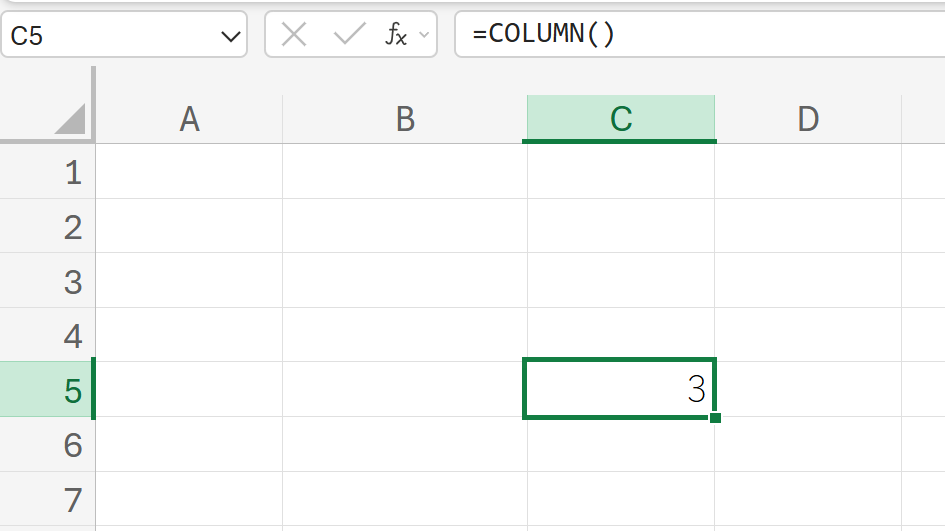
解説:
COLUMN()と引数を省略すると、その数式が入力されている現在のセルの列番号(C列は3番目なので3)を返します。
33. COLUMNS
概要:
指定したセル範囲に含まれる列の数を返します。
構文:
=COLUMNS(配列)
例題:
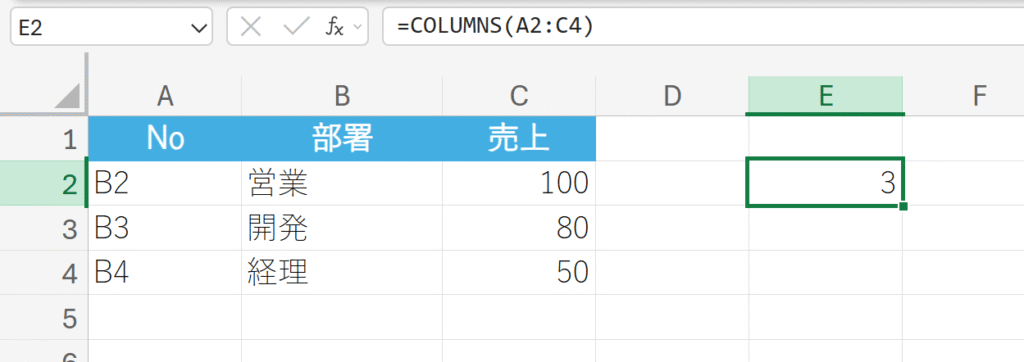
データ範囲の列数をカウントする
解説:
A列、 B列、 C列の3つの列があるため、3が返されます。参照に空のセルが含まれていても、参照範囲内のすべての列がカウントされます。
34. INDIRECT
概要:
テキスト文字列で指定されたセル参照を返します。文字列をセル参照として評価する際に使われます。
構文:
=INDIRECT(参照文字列,[A1形式])
例題:
テキスト文字列をセル参照として評価する。
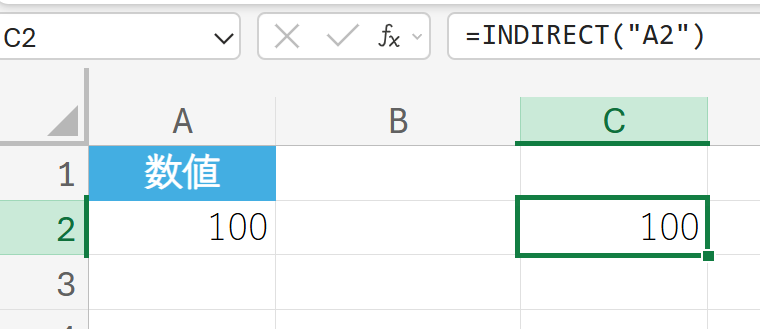
解説:
INDIRECT関数は、引数として渡されたテキスト”A2″を、単なる文字列ではなく、実際にセルA2を参照するように評価します。結果として、A1セルの値である”100″が返されます。
35. OFFSET
概要:
基準となるセルから、指定した行数と列数だけ離れた位置にあるセルまたはセル範囲を返します。
構文:
=OFFSET(基準,行数,列数,[高さ],[幅])
例題:
特定のセルを参照する。
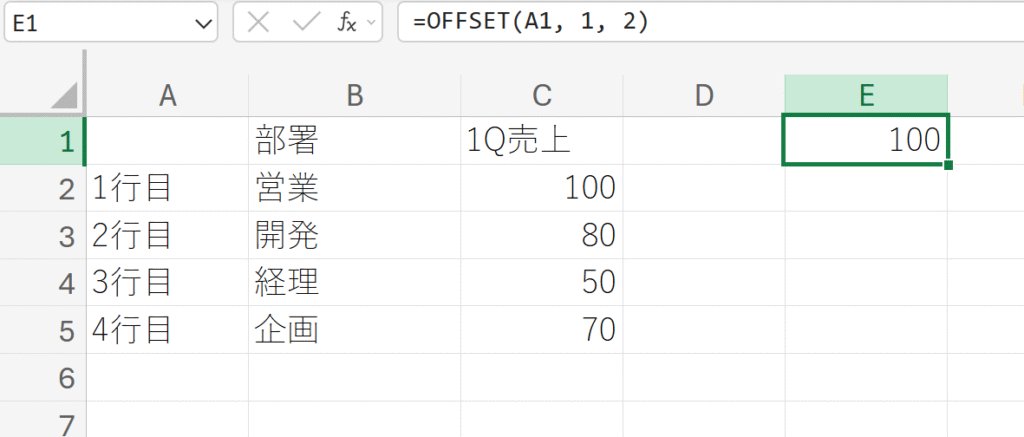
解説:
A1から始まり、下に1行、右に2列移動したセルはC2であり、そのセルの値である”100″が返されます。
36. CHOOSE
概要:
指定したインデックス番号に基づき、引数リストの中から選択された値を返します。
構文:
=CHOOSE(インデックス,値1,[値2,…])
例題:
インデックス番号で曜日を返す。

解説:
インデックスが3なので、引数で渡された3番目の値である “水” が返されます。
37. AREAS
概要:
参照に含まれる領域(範囲)の数を返します。複数の範囲をカンマで区切って指定した場合などに使われます。
構文:
=AREAS(参照)
例題:
非連続な複数の範囲に含まれる領域の数を取得する。
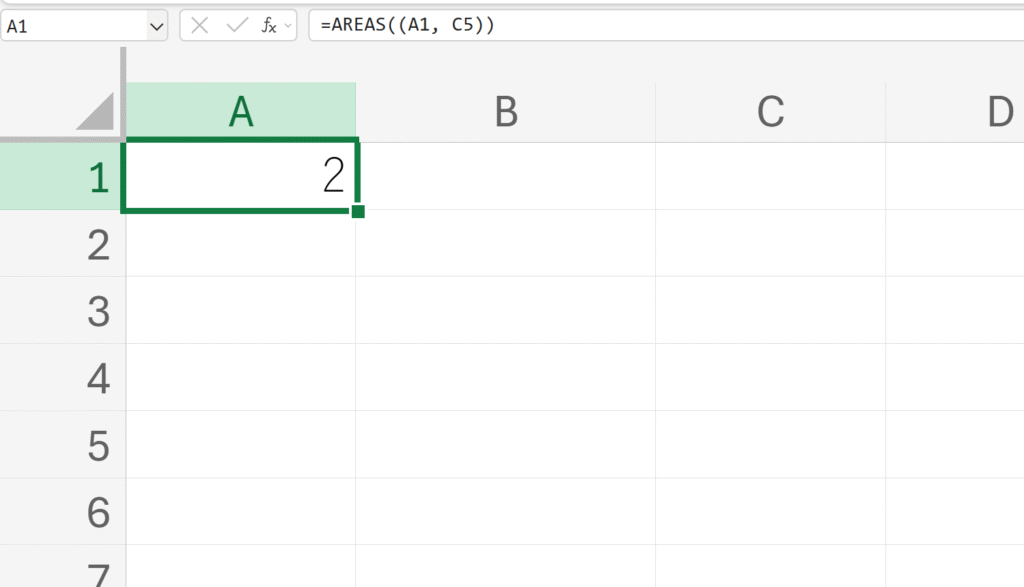
解説:
A1とC5はそれぞれが独立した一つの領域として数えられるため、合計で2領域としてカウントされます。
38. FORMULATEXT
概要:
指定したセルに含まれる数式をテキスト(文字列)として返します。
構文:
=FORMULATEXT(参照)
例題:
数式の結果ではなく、数式自体を文字列として取得する。
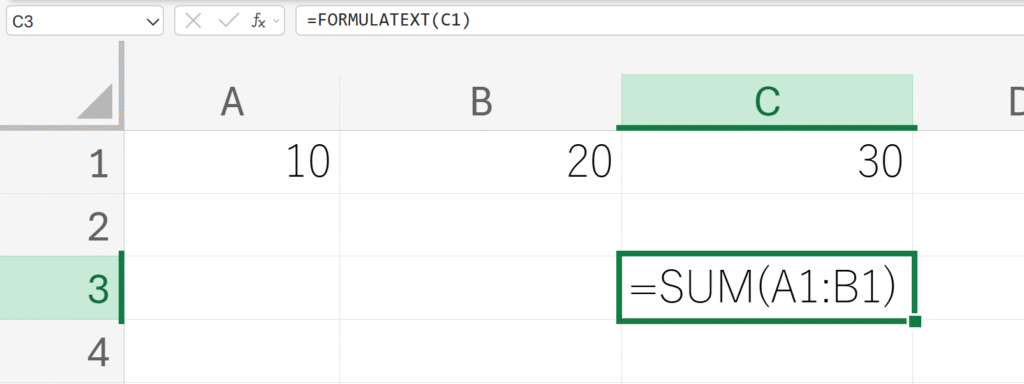
解説:
C1セルには値として30が表示されていますが、FORMULATEXT関数は、その裏にある=SUM(A1:B1)という数式をテキストとして返します。
39. HYPERLINK
概要:
クリックすると指定されたリンク先にジャンプするハイパーリンクを作成します。
構文:
=HYPERLINK(リンク先,[表示名])
例題:
外部ウェブサイトへのリンクを作成する。
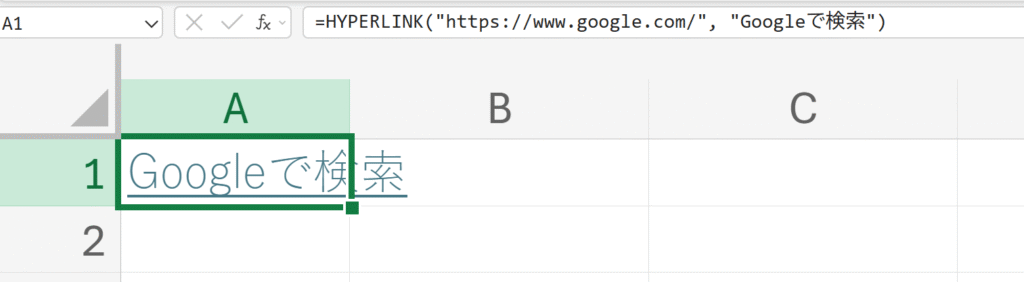
解説:
リンク先は、必ずダブルクォーテーションで囲まれた文字列として指定する必要があります。
40. IMAGE
概要:
セルの中に画像を表示します。画像のURLを指定する必要があります。
構文:
=IMAGE(リンク,[代替テキスト,…])
例題:
最も基本的な使い方として、画像のURLを指定してセルに画像を表示します。
数式:
=IMAGE(“https://example.com/logo.png”, “会社ロゴ”)
解説:
数式を入力したセルに、指定したURLにある画像が表示されます。画像が表示されない環境では、「会社ロゴ」という代替テキストが表示されます。
41. TRIMRANGE
概要:
配列の周囲にある空白の行や列をトリミング(除去)し、データが入力されている最小のセル範囲を返します。
構文:
=TRIMRANGE(配列)
例題:
範囲A1:E8全体を指定し、データが入っている部分のみを取り出します。
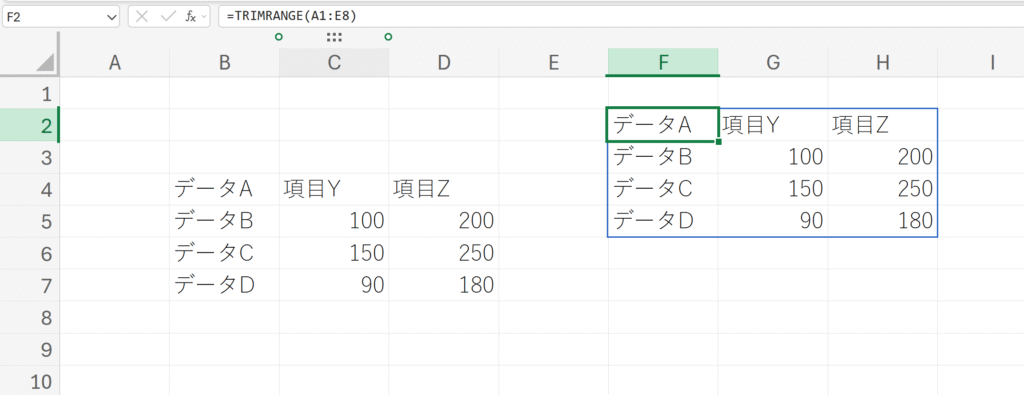
解説:
TRIMRANGEは、指定されたA1:E8の範囲をスキャンします。データが含まれていないA列、E列、1行目、2行目、7行目、8行目を自動的にトリミング(除去)します。結果として、データが実際に含まれているB3:D6の範囲が、新しい配列として抽出されます。
まとめ:検索と行列関数を使いこなすステップ
全41種類の関数を見てきましたが、いきなりすべてを覚える必要はありません。まず抑えるべきは、以下の新世代の主要関数です。
- XLOOKUP: 従来のVLOOKUP、HLOOKUP、INDEX/MATCHのほぼ全てを置き換えられる最強の検索関数です。
- FILTER: 条件に合ったデータを瞬時に抽出し、新しいリストを作成するデータ抽出の核となる関数です。
- UNIQUE: 重複を自動で排除し、動的なドロップダウンリスト作成などに欠かせません。
- VSTACK/HSTACK: 複数のリストや表を結合する作業の手間をゼロにします。
これらの関数はスピル機能に対応しているため、一つセルに入力するだけで、結果が複数のセルに自動展開される便利さをぜひ体感してください。
この記事を「Excel作業で困ったときの辞書」として活用し、一つずつ関数の使い方をマスターして、あなたの業務効率を飛躍的に向上させましょう!
📚 Excelをもっと学びたい方へ
Excelスキルが向上すると、
など、日々の仕事が格段に楽になります。
しかし、Excelスキルは目に見えにくいため、転職や昇進の場面で正しく評価されないことも少なくありません。
そこでおすすめなのが、Excelスキルを客観的に証明できるMOS資格です。
MOS資格を本気で取得したい方へ
Excelを実務レベルで使いこなしたいなら、MOS資格の取得がおすすめです。MOSはExcelスキルを客観的に証明できるため、転職や昇進でも高く評価されます。
ハロー!パソコン教室のMOS対策講座は、初心者でも合格を目指せるオンライン講座です。
ハロー!パソコン教室 MOS対策講座の特徴
こんな方におすすめ
独学に不安がある方は、公式サイトで講座内容を確認してみてください。
\ Excelスキルを証明するならMOS資格 /




コメント